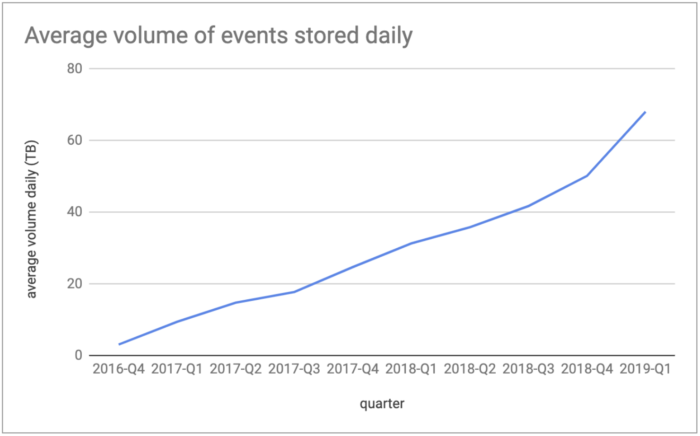
为了应对这种规模,Spotify 在过去六年中不得不两次升级EDI。
在2016年的第一次升级之前,Spotify的EDI是围绕具有两个主要组件的本地系统构建的:
(1)一个Kafka流处理系统,收集日志并完成推送。
(2)一个Hadoop集群,它使用Hive和Avro格式在HDFS上以一小时的分区存储摄取的事件流 。
2016年之前的EDI版本每秒可以轻松处理多达700,000个事件。除了增长的限制之外,这种基础设施还存在一些问题。首先,数据作业只从每个小时长的分区中读取一次数据。由于网络或软件问题而中断的数据流不会被回填,因为它会为EDI创建太多额外的重新处理以正确存储它。这导致数据不完整和不准确。
其次,EDI是围绕不能持久化或存储事件的旧版Kafka设计的。这意味着事件数据仅在写入Hadoop后才会保留,这使得Hadoop成为所有EDI的单点故障。“如果Hadoop宕机,整个事件传递系统就会停止。” Spotify的工程师写道。
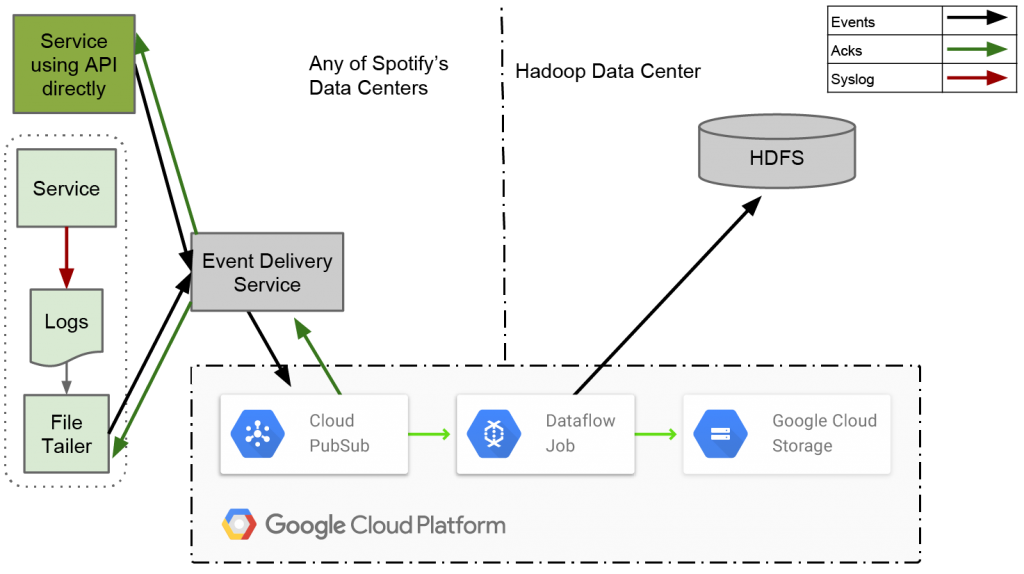
随着事件数量的增加,此类系统停顿和中断也随之增加。为了解决这个问题,Spotify决定将事件交付基础架构迁移到云端——谷歌云。








Thanks for sharing. I read many of your blog posts, cool, your blog is very good. https://accounts.binance.com/ka-GE/register-person?ref=OMM3XK51
Your point of view caught my eye and was very interesting. Thanks. I have a question for you. https://accounts.binance.com/en/register?ref=P9L9FQKY
Can you be more specific about the content of your enticle? After reading it, I still have some doubts. Hope you can help me. https://accounts.binance.com/en/register?ref=53551167
I may need your help. I tried many ways but couldn’t solve it, but after reading your article, I think you have a way to help me. I’m looking forward for your reply. Thanks.