深度学习模型训练的主要设计目标,也是Weka人工智能数据平台的设计目标,即是通过在存储学习数据的WEKA文件系统中以最低的延迟提供最高的吞吐量,使进行训练处理的GPU持续饱和。深度学习模型能够学习的数据越多,它就能越快地收敛于一个解决方案,其准确性也就越高。
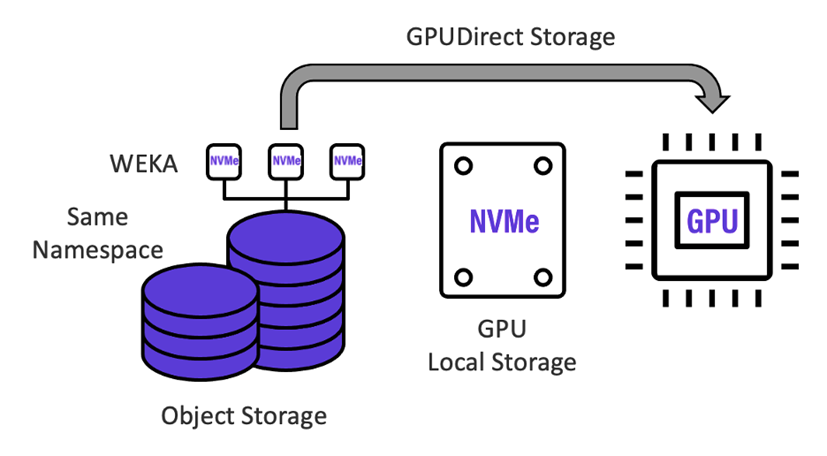
WEKA将典型的GPU匮乏的“multi-hop”AI数据管道折叠成一个单一的、零拷贝的高性能AI数据平台–其中大容量对象存储与高速WEKA存储 “融合 “在一起,共享同一命名空间,并由GPU通过NVIDIA GPUDirect Storage协议直接访问,消除了所有瓶颈,如下图所示。将用于人工智能的WEKA数据平台纳入深度学习数据管道,可使数据传输率达到饱和,并消除存储仓之间浪费的数据复制和传输时间,使每天可分析的训练数据集数量呈几何级数增加。










I don’t think the title of your article matches the content lol. Just kidding, mainly because I had some doubts after reading the article.
Your article made me suddenly realize that I am writing a thesis on gate.io. After reading your article, I have a different way of thinking, thank you. However, I still have some doubts, can you help me? Thanks.