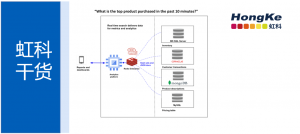
GPU支持大规模并行,每个核心都专注于高效计算,从而大幅降低基础设施成本,并为端到端数据科学工作流提供卓越的性能。12个当前的NMDIA GPU可以提供2000个现代GPU的深度学习性能。在同一台服务器上增加8个GPU可以提供多达55,000个额外的核心。虽然 GPU可以加速你的计算过程,但研究表明,它们有一半的时间在等待数据,这意味着你最终要等待结果。它们提供的计算能力的增长需要更强大的网络和存储。多达70%的时代发生在GPU之前。在我们的数据管道的不同阶段,在系统之间复制数据花费了大量的时间——NAS用于持久存储,本地文件系统或并行文件系统用于快速存储,对象存储用于归档数据。这使得让你的GPU在更低的epoch时间和更快的时间内充分利用变得具有挑战性。
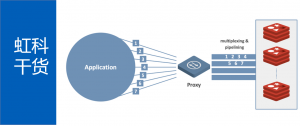
WEKA的人工智能数据平台解决了当今企业技术计算工作负载和其他高性能应用程序所带来的存储挑战,这些应用程序运行在本地、云端或平台之间。零拷贝架构在相同的存储后端运行整个管道,并消除了副本的成本和延迟。
通过WEKA,您可以加速GPU支持的数据管道的每个步骤――从数据摄取、清理到建模、训练验证和推断,以加速业务结果。