NITRO 可与现有调度程序一起使用
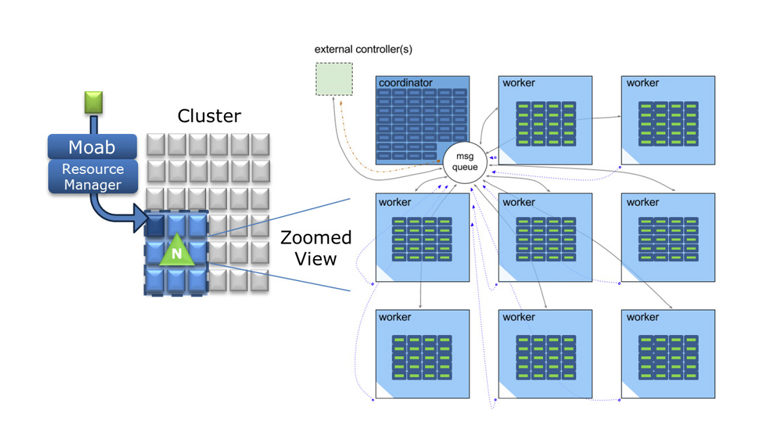
Nitro 与其他 HPC 调度程序共存,例如 Platform LSF、PBS Pro、Moab/TORQUE、UGE 和 SLURM。由于 Nitro 的分阶段协调器 – 工作者架构,Nitro 吞吐量随着分配给会话的核心数量而增加。使用简单的语法:一行 = 一个任务,一行包含一个可执行命令。如果当前的 HTC 作业语法需要转换,可以创建一个任务过滤器以自动重新格式化为“任务”定义语法。当 Nitro 与 Moab、TORQUE 或 SLURM 一起使用时,它可以与 Viewpoint 门户集成,以便于使用和更简化的提交和管理。
最佳使用
Nitro 对于希望大幅提高串行作业或单节点并行作业(运行数毫秒到数分钟)的吞吐量的管理员来说非常有价值,尽管运行时间较长的用例也可以看到 Nitro 的好处。在多个用例中,即使一小部分工作负载与 Nitro 涵盖的高吞吐量用例相匹配,运行 Nitro 仍然可以获得显着的整体系统效率。