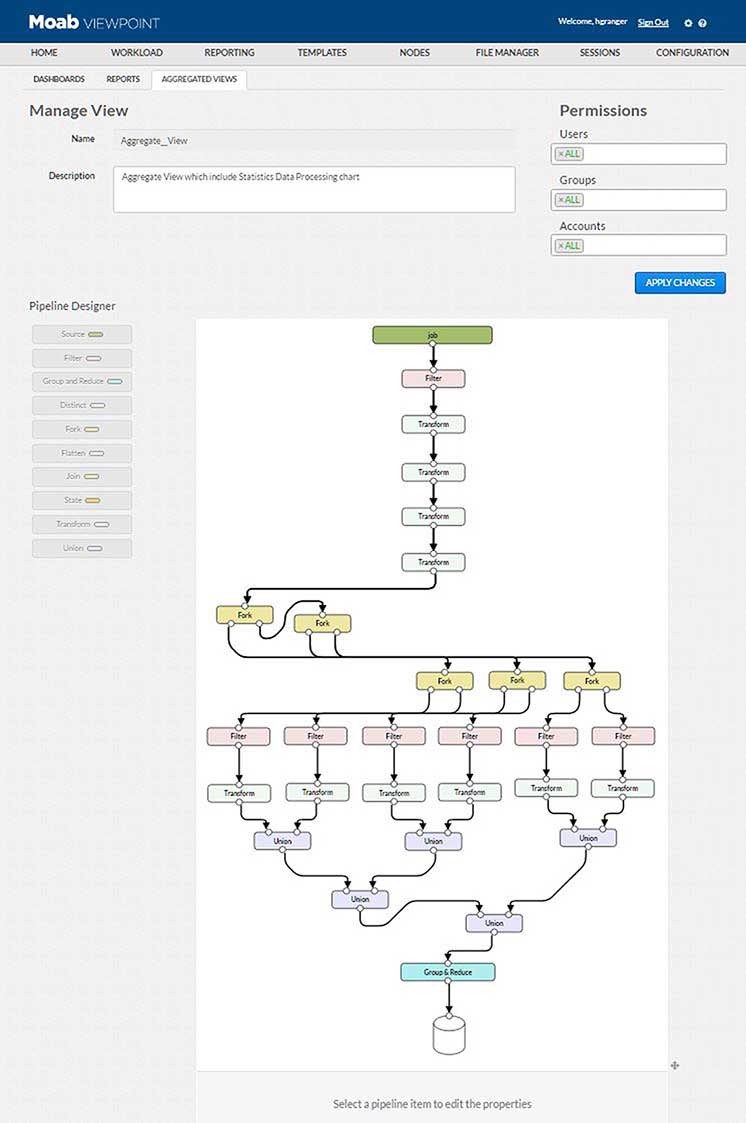
报告引擎生成 JSON 数据流,可以使用传统的数据分析功能(如分组、归约、连接、过滤等)进行扩充。然后将这些流存储在数据库集合中。Adaptive Computing 的报告引擎基于 Apache Spark,并存储在我们的 MongoDB 数据库中,以最大限度地提高可扩展性和性能。
报告
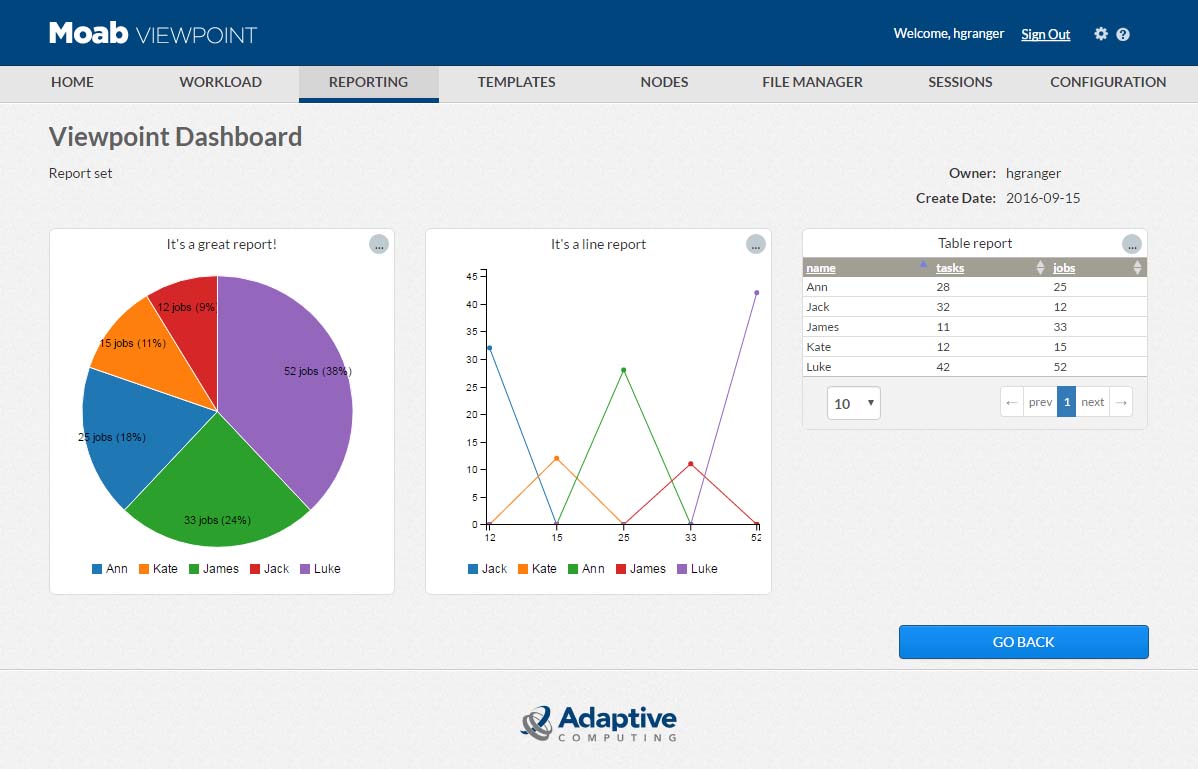
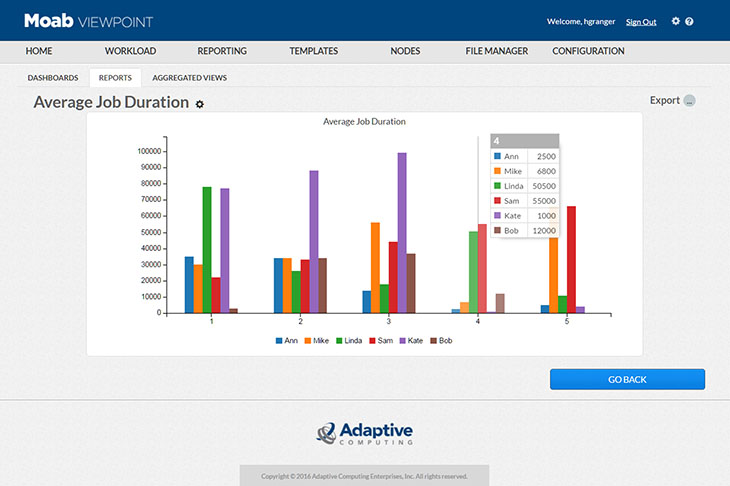
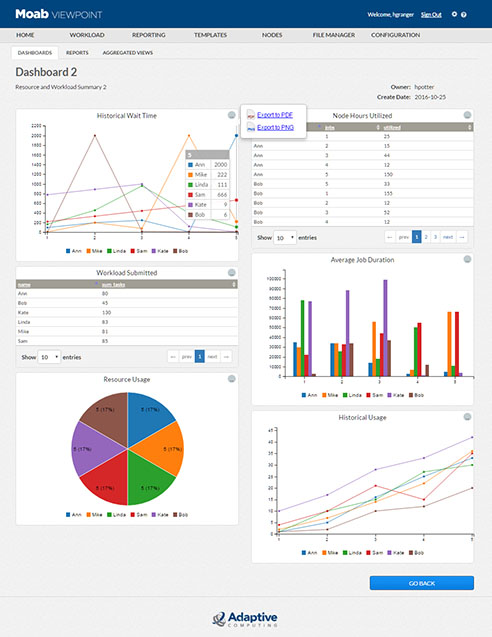
要创建新报告,用户需要选择他们有权访问的聚合视图。然后,他们使用 SQL 查询编辑器指定数据字段、详细粒度、输出(图表或表格),并在创建结果图表之前对其进行预览。结果可以作为报告单独应用,实施到仪表板中,或导出为 .pdf、.csv 或图像文件。运行报告时,用户指定刷新率并传递过滤结果的输入(时间范围、用户、用户组)。