性能
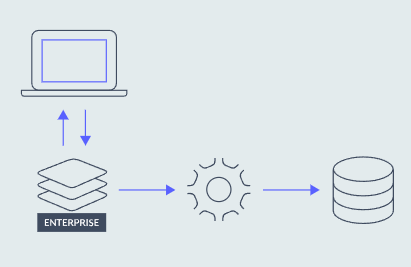
缓存层必须提供的第一个要求是任何负载下的高性能。 研究表明,为了让用户感知“即时”体验,端到端响应时间必须在 100 毫秒以内。简而言之,高性能缓存层必须始终如一地以低延迟提供高吞吐量,以避免成为性能瓶颈。

可扩展性
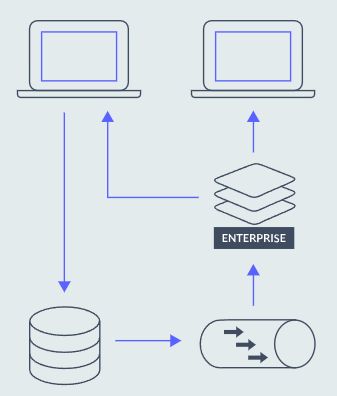
高性能缓存层应该能够扩展并满足业务增长或突然激增(如情人节、黑色星期五、自然灾害或流行病)产生的需求。此外,应在不导致停机或离线迁移的情况下动态完成可扩展性,而不会增加响应时间。
多云和地理分布
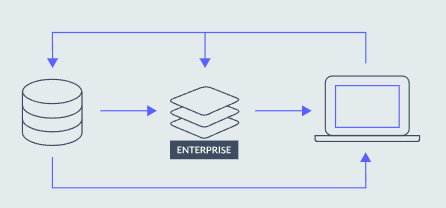
越来越多的组织正在采用多云策略,无论是避免供应商锁定还是利用各种云提供商的最佳工具。但是,管理一个地理上分布式的缓存系统要更具挑战性,该系统既要保证亚毫秒级的延迟,又要解决跨多个云的数据集冲突。